Jens Albrecht, Sidart Ramachandran, Christian Winkler, Blueprints for Text Analytics Using Python, 심상진, Hanbit Media-OREILLY (2022), p29-68.
EDA
- 탐색적 데이터 분석
- 설문조사 수준의 데이터(요약, 통계, 결측값 등)를 체계적으로 검토하는 과정
- NLP에서 통계 검색은 말뭉치에서 수행됩니다.
- 메타데이터: 범주, 작성자, 날짜/시간
- 내용: 단어, 구, 사물 -> 상대 빈도 사용
- 단어: 문장의 공백 단위
- 전. 나는 / 만났다 / 친구를 / 도서관에서
- 구: 술어 없이 하나의 단어로 사용되는 두 개 이상의 단어 덩어리.
- 전. 귀여운 강아지(명사구), 많이 먹는다(동사구)
- 문장: 주어+술어 덩어리, 종결어미가 없어 문장으로 완전하지 않음
- 단어: 문장의 공백 단위
- 점수: 인기도, 정서, 가독성 -> 역시 모델에서 도출
데이터 샘플링
- 샘플링: df.sample(frac=0.1)
- 무작위 추출 10% -> 메인 메모리에 로드
개요를 확인하세요
- 메모리, 데이터 유형: df.info()
- 요약 통계:
- 숫자: df.describe()
- 범주형: df.describe(include=”O”)
- 누락된 값의 수: df.isna().sum()
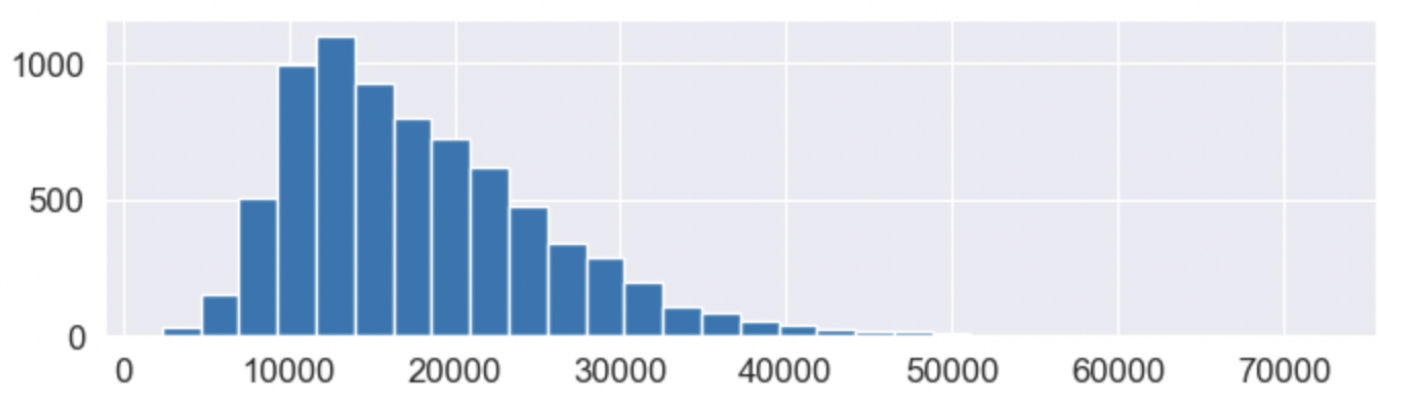
데이터 배포
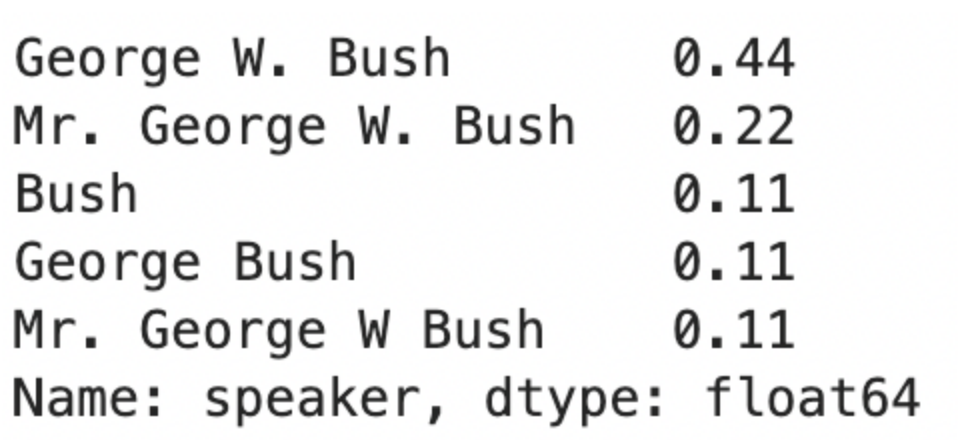
범주형 변수(빈도)
- 빈도: df(열 이름).value_counts()

- 빈도 비율: df(열 이름).value_counts(normalize=True)
- 상자 그림: df(열 이름).plot(종류=’상자’, vert=False, figsize=(8, 1))
- vert: vertical -> 틀리면 가로로 그립니다.

- 히스토그램: df(열 이름).hist(bins=30, figsize=(8,2))
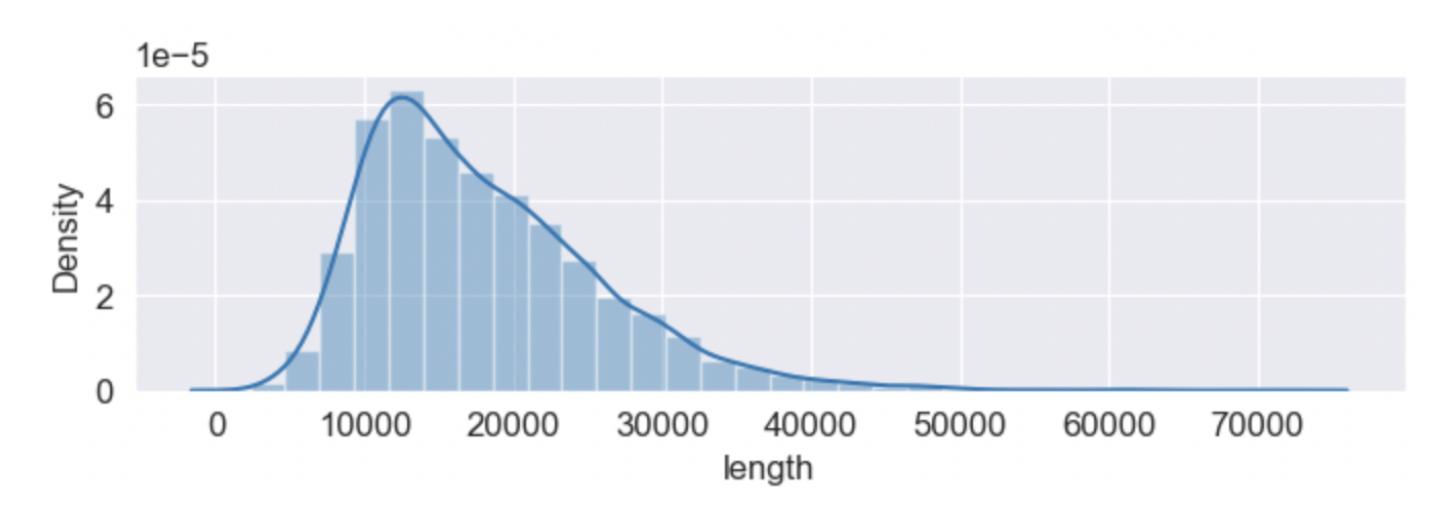
- seaborn distplot: sns.distplot(df(열 이름), bins=30, kde=True)
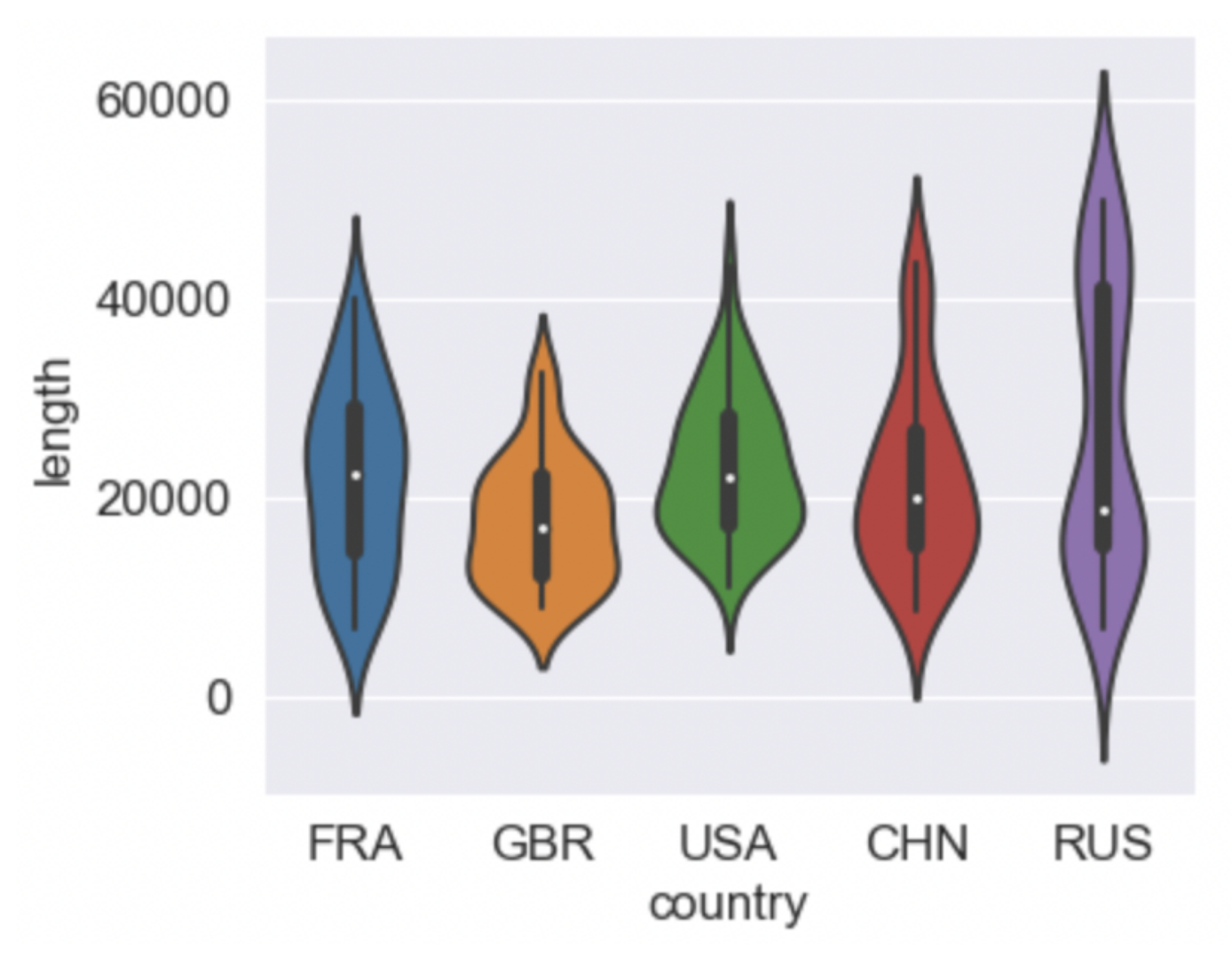
- seaborn violinplot: sns.catplot(data=df, x=열 이름, y=열 이름, 종류=’바이올린’)
시간 리샘플링
- pandas 시리즈 개체의 ‘dt’ 접근자 사용
- 유형
- dt.date: 날짜 추출
- dt.year: 연도 추출
- dt.Quarter: 분기 추출
- dt.hour: 시간 추출
- dt.month: 월 추출
- dt.week: 주 추출
- dt.strftime(형식): 원하는 날짜 형식을 지정합니다.
- Panda의 내장 함수 “Resample”을 사용합니다.
- 일간/주간/월간 단위로 집계 및 처리 가능
전처리 파이프라인
- 1단계: 변환(대문자 -> 소문자)
- 2단계: 토큰화: 예: 공백 또는 정규식 사용
- 지도 적용 기능 사용
- 맵: 단일 열 변환
- 적용: 1단, 다단 변환 가능
- applymap: 모든 데이터 셀 적용
- 지도 적용 기능 사용
- 3단계: 불용어 제거
- 중지 단어: 자주 발생하지만 많은 정보를 전달하지 않는 단어(예: 부사, 대명사 등)
- nltk 중지 단어가 자주 사용됨 nltk.corpus.stopwords.words(‘english’)
- 반드시 제거해서는 안 됨 -> 불용어는 긍정적/부정적 의미를 가지며 전체의 중요한 부분 중 중요한 부분이 될 수 있음
- 전. I don’t like cheese에서 don’t는 중지 단어이지만 부정은 not에서 파생될 수 있습니다.
- 불용어 목록을 사용하는 대신 문서(사용 중인 데이터) 내에서 빈도가 80% 이상인 단어를 처리하는 것이 유용할 수 있습니다.
토큰화
- 주어진 코퍼스를 토큰이라는 단위로 나누는 작업입니다.
- 토큰 표준은 여러 가지 방법으로 설정할 수 있습니다. B. 단어, 구, 문장 및 문자열.
- 단어 기호
- 영어는 장소별로 쉽게 구분할 수 있습니다.
- 한글은 교착어이기 때문에 공백으로 구분할 수 없습니다.
- 교착어(agglutinative language): 조사, 어미 등을 더해 단어를 형성하는 언어.
전. 영어: 그/그, 한국어: 그, 그, 그, 그, 그 - 한국어에는 조사와 같이 접미사가 붙는 것이 많기 때문에 모두 분리해야 합니다.
- 형태소로 구분해야 함
- 교착어(agglutinative language): 조사, 어미 등을 더해 단어를 형성하는 언어.
단어 빈도 분석
- 반대 클래스
- 물건의 수를 세다
- 토큰 목록은 계속 업데이트될 수 있습니다.
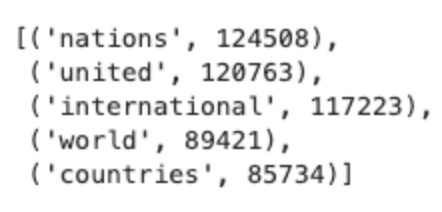
- most_common을 사용하여 가장 일반적인 단어를 찾을 수 있습니다.
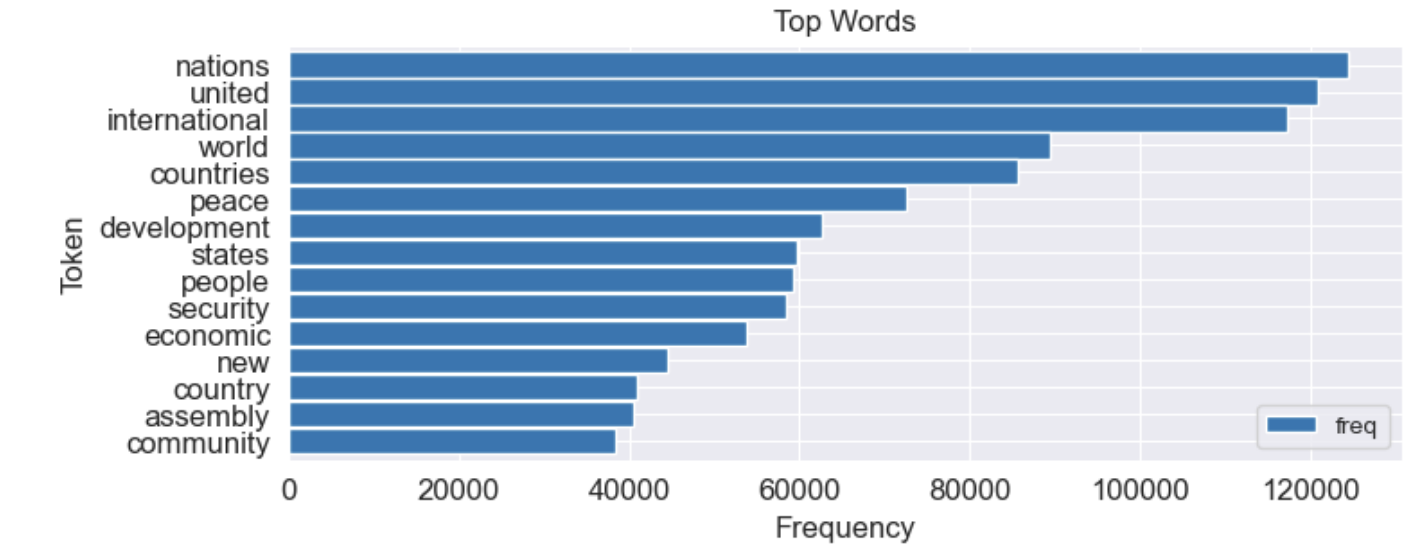
- 주파수 차트
- 단어 구름
- 다양한 글꼴 크기로 빈도 시각화
- 콘텐츠가 이해하기 쉽고 비교 가능하지만 정확하지 않음

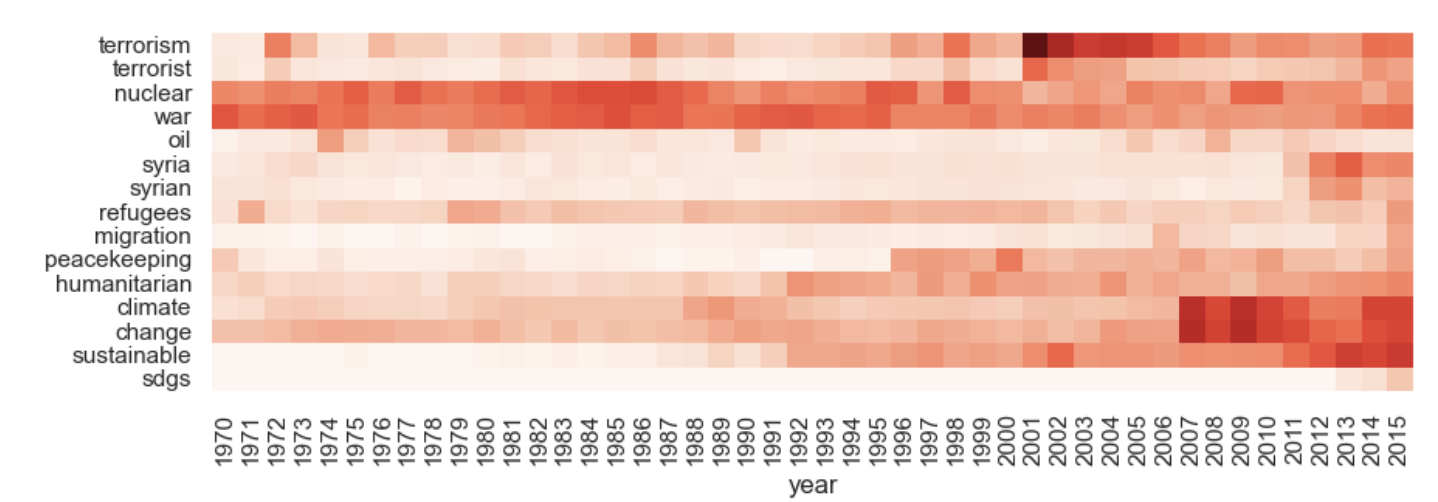
- 히트맵
TF-IDF
- 전반적으로 가장 일반적인 단어보다. “개별 날짜에만” 흔한 말이 더 중요하다
- TF: 용어 빈도
- tf(d,t): 특정 문서(d)에서 특정 단어
- IDF: 역 문서 빈도
- df
- 일반적인 용어의 영향을 줄이기 위해 사용
- 대수 스케일링 처리 -> 희귀 단어가 매우 높은 점수를 받는 것을 방지합니다.
- 예: 문서 수(n) = 1,000,000인 경우

- 일반적으로 분모가 0이 되는 것을 방지하기 위해 1을 더합니다.
$$idf - TF * IDF: 특정 문서에만 자주 등장하는 단어가 높은 값을 가짐
컨텍스트에서 키워드 검사
- 문맥의 키워드(KWIC)
- nltk 또는 textacy 사용
- textacy.extract.kwic.keyword_in_context
- 시각화 결과(워드 클라우드, 빈도 차트 등)를 보고 알 수 없는 토큰에 대한 세부 정보를 살펴봐야 합니다.
- 약어? 전처리의 결과? 등.
- 키워드의 왼쪽과 오른쪽에 특정 수의 단어 나열
- SDGs가 “지속 가능한 개발 목표”임을 알 수 있습니다.

- SDGs가 “지속 가능한 개발 목표”임을 알 수 있습니다.
n-그램
- 문서/문장 내에서 정확한 의미를 찾기 위해 두 개 이상의 단어 조합을 살펴봐야 할 수도 있습니다.
- 전. 연결, 배열
- 자기 확신
- 기후 변화
- 단어 수에 따른 이름 분류
- 1단어의 조합: unigram
- 두 단어의 조합: Bigram
- 세 단어의 조합: trigram
- 3개 이하의 ngram 권장(n이 증가함에 따라 조합 수가 기하급수적으로 증가하기 때문)
- 전치사 및 수식어와 같은 불용어를 제거하고 조합을 찾는 것이 좋습니다.
- 중지 단어를 제거하고 n-gram을 실행하면 먼저 원본 텍스트에 없는 n-gram이 생성됩니다.
먼저 n-gram을 실행한 다음 중지 단어를 제거하는 것이 좋습니다.
- 중지 단어를 제거하고 n-gram을 실행하면 먼저 원본 텍스트에 없는 n-gram이 생성됩니다.